|
I am interested in computer vision and autonomous driving. My current research focuses on: |

|
|
|
|
*Equal contribution †Project leader/Corresponding author. |
|
|
|
|
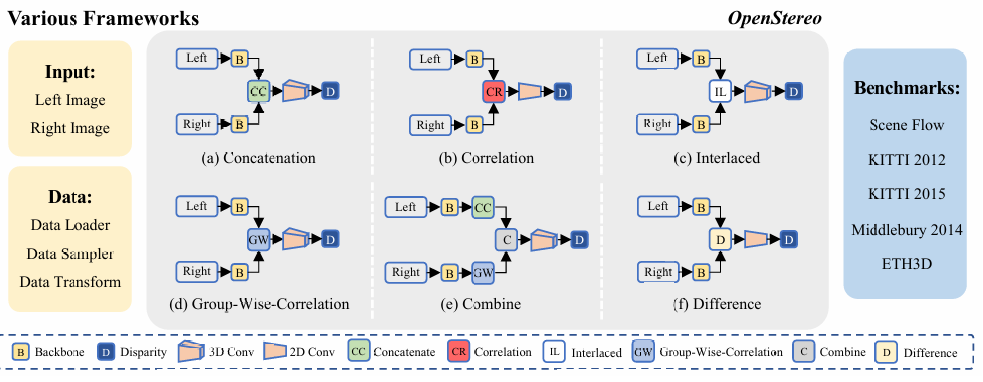
Xianda Guo, Chenming Zhang, Juntao Lu, Yiqun Duan , Yiqi Wang , Tian Yang, Zheng Zhu, Long Chen arXiv, 2024. [arXiv] [Code] OpenStereo includes training and inference codes of more than 10 network models, making it, to our knowledge, the most complete stereo matching toolbox available. |
|
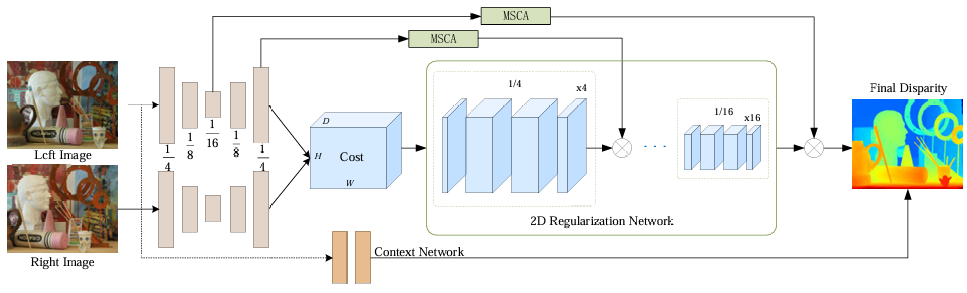
Xianda Guo*, Chenming Zhang*, Youmin Zhang , Wenzhao Zheng, Dujun Nie , Matteo Poggi , Long Chen ICRA, 2025. [arXiv] [Code] We present LightStereo, a cutting-edge stereo-matching network crafted to accelerate the matching process. |

|
Xianda Guo*, Chenming Zhang*, Youmin Zhang Ruilin Wang, Dujun Nie, Wenzhao Zheng, Matteo Poggi, Hao Zhao, Mang Ye, Qin Zou, Long Chen arXiv, 2025. [arXiv] [Code] We introduce a novel synthetic dataset that complements existing data by adding variability in baselines, camera angles, and scene types. We extensively evaluate the zero-shot capabilities of our model on five public datasets, showcasing its impressive ability to generalize to new, unseen data. |

|
Xianda Guo*, Chenming Zhang*, Ruilin Wang, Youmin Zhang Wenzhao Zheng, Matteo Poggi, Hao Zhao, Qin Zou, Long Chen arXiv, 2025. [arXiv] [Code] We present StereoCarla, a high-fidelity synthetic stereo dataset specifically designed for autonomous driving scenarios. Built on the CARLA simulator, StereoCarla incorporates a wide range of camera configurations, including diverse baselines, viewpoints, and sensor placements as well as varied environmental conditions such as lighting changes, weather effects, and road geometries. |
|
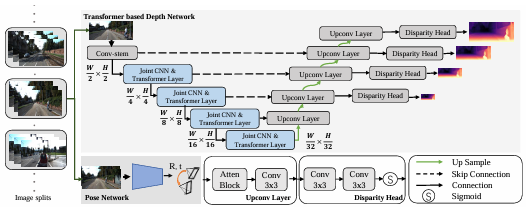
Chaoqiang Zhao *, Youmin Zhang*, Matteo Poggi, Fabio Tosi, Xianda Guo, Tao Huang, Zheng Zhu, Guan Huang, Tian Yang , Stefano Mattoccia , 3DV, 2022. [arXiv] [Code] In light of the recent successes achieved by Vision Transformers (ViTs), we propose MonoViT, a brand-new framework combining the global reasoning enabled by ViT models with the flexibility of self-supervised monocular depth estimation. |
|
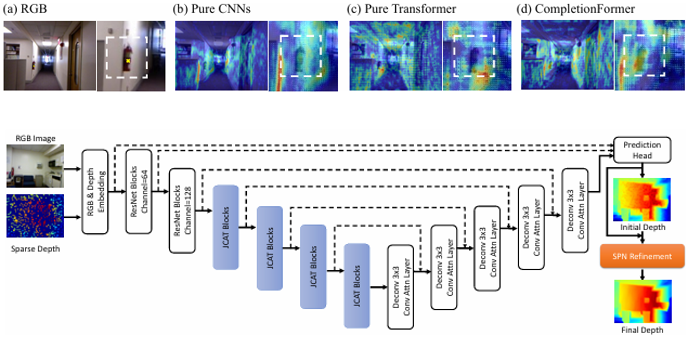
Youmin Zhang, Xianda Guo, Matteo Poggi, Zheng Zhu, Guan Huang, Stefano Mattoccia , CVPR, 2023. [arXiv] [Code] This paper proposes a Joint Convolutional Attention and Transformer block (JCAT), which deeply couples the convolutional attention layer and Vision Transformer into one block, as the basic unit to construct our depth completion model in a pyramidal structure. |
|
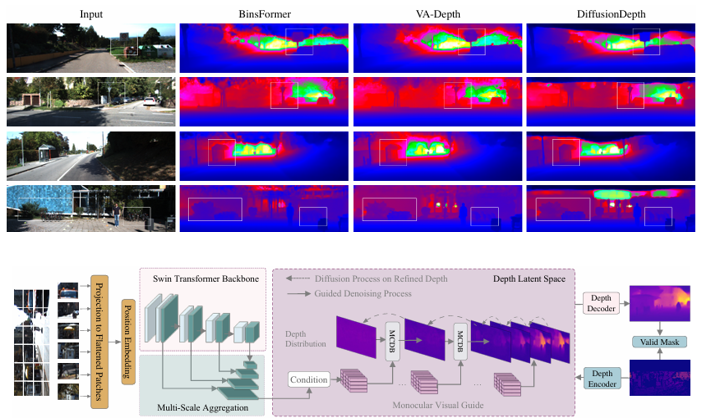
Yiqun Duan, Xianda Guo†, Zheng Zhu ECCV, 2024. [arXiv] [Code] We propose DiffusionDepth, a new approach that reformulates monocular depth estimation as a denoising diffusion process. It learns an iterative denoising process to `denoise' random depth distribution into a depth map with the guidance of monocular visual conditions. |
|
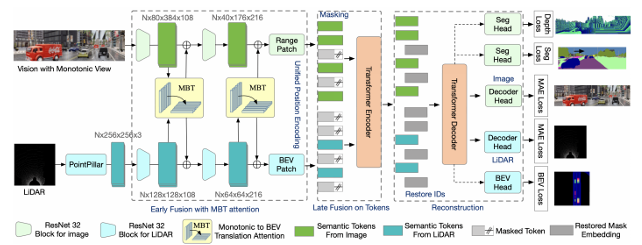
Yiqun Duan, Xianda Guo, Zheng Zhu, Yao Zheng*, Zhen Wang, Yu-Kai Wang, Chin-Teng Lin arXiv, 2024. [arXiv] [Code] This paper proposes MaskFuser, which tokenizes various modalities into a unified semantic feature space and provides a joint representation for further behavior cloning in driving contexts. Given the unified token representation, MaskFuser is the first work to introduce cross-modality masked auto-encoder training. |
|
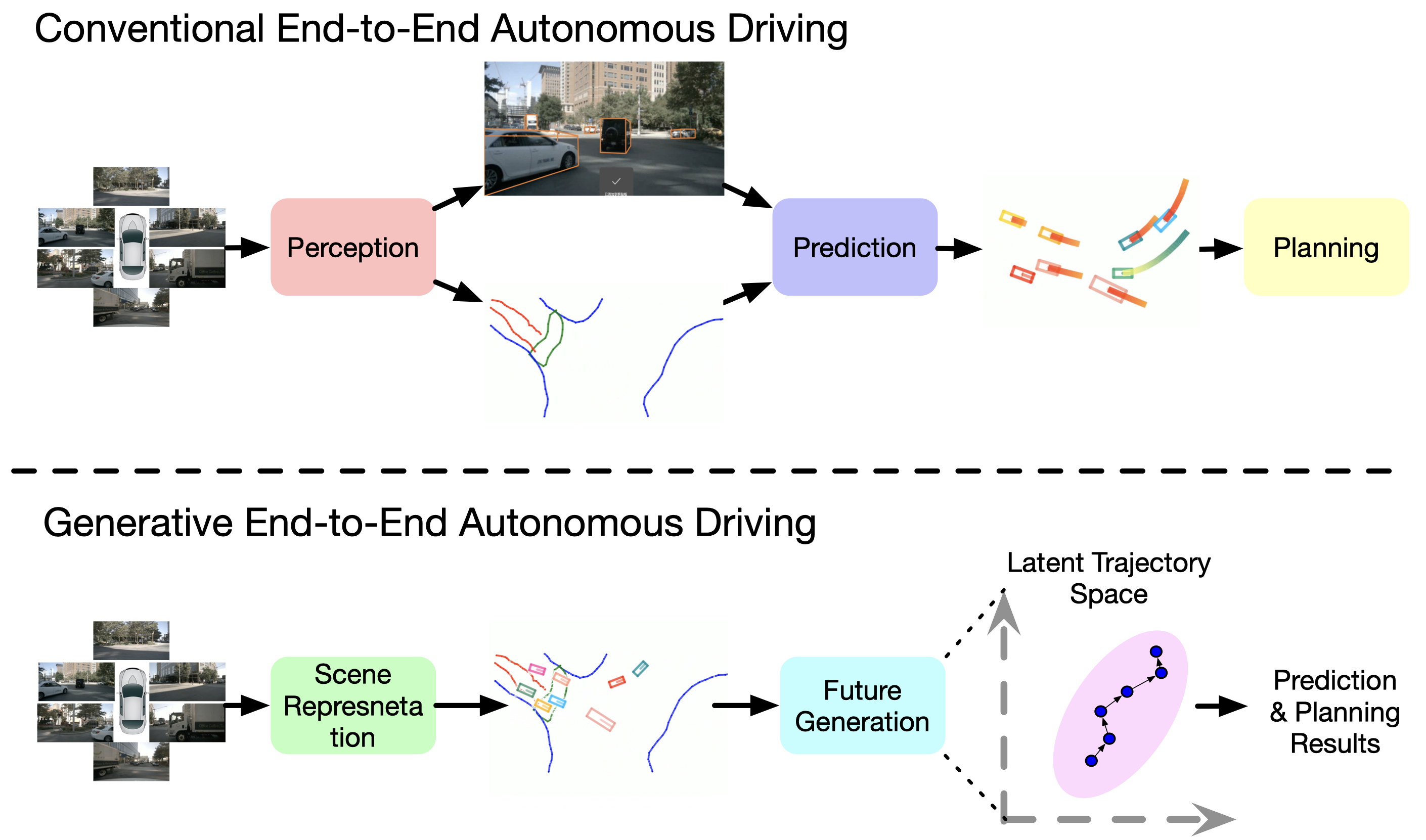
Wenzhao Zheng*, Ruiqi Song* , Xianda Guo*†, Chenming Zhang , Long Chen ECCV, 2024. [arXiv] [Code] GenAD casts end-to-end autonomous driving as a generative modeling problem. |
|
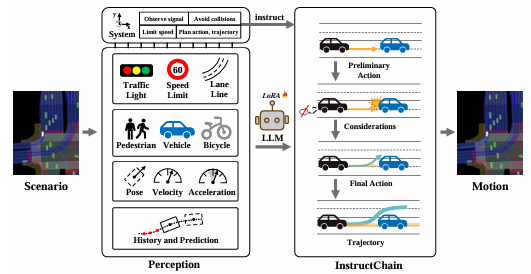
Ruijun Zhang*, Xianda Guo*†, Wenzhao Zheng*, Chenming Zhang , Kurt Keutzer , Long Chen arXiv, 2024. [arXiv] [Code] In this paper, we propose an InstructDriver method to transform LLM into a motion planner with explicit instruction tuning to align its behavior with humans. |

|
Xianda Guo*, Ruijun Zhang* , Yiqun Duan* , Yuhang He , Dujun Nie , Wenke Huang , Chenming Zhang , Shuai Liu, Hao Zhao, Long Chen NeurIPS, 2025. [arXiv] [Code] We introduce DriveMLLM, a benchmark specifically designed to evaluate the spatial understanding capabilities of multimodal large language models (MLLMs) in autonomous driving. |
|
|
|
|